AI 时代要淘汰的是码农,不是软件工程师。码农的价值在于把确定的需求翻译成代码,这件事 AI 越来越擅长。但软件工程师的价值在于面对模糊问题时的判断力。这种判断力不会因为 AI 写代码快了就贬值,反而会更值钱。

我做了十几年后端和架构工作,一直觉得自己对技术是有积累的。直到最近遇到一道面试题——设计一个海量游戏排行榜系统——才发现自己回答得一塌糊涂。
事后复盘,原因有两层。
表面原因是临场发挥差。我几乎没有做过系统设计类的面试题,平时的经验都是在真实项目中一点一点磨出来的,从来没有被要求在几分钟内把一个系统从零讲清楚。没有练过,自然紧张;一紧张,脑子里的东西就串不成线。
深层原因更值得正视:我确实没有系统地、完整地思考过这类问题。日常工作中,系统是一点一点长出来的,很多决策分散在几个月甚至几年里。但面试要求你在极短时间内展现全局视角,这恰恰暴露了"做过"和"想清楚"之间的差距。
这件事让我想起前段时间看到的清华大学一场讲座。有位教授说,AI 时代要淘汰的是码农,不是软件工程师。码农的价值在于把确定的需求翻译成代码,这件事 AI 越来越擅长。但软件工程师的价值在于面对模糊问题时的判断力 ——该拆还是该合,该强一致还是最终一致,该用什么数据结构、什么存储、什么架构,以及为什么。
这种判断力不会因为 AI 写代码快了就贬值,反而会更值钱。
所以我决定把这道让我翻车的题拿出来,静下心重新想一遍。不是为了背一个标准答案,而是想把从问题到方案的思考过程完整走一遍。如果你也在准备类似的面试,或者想锻炼自己的系统设计能力,希望这篇文章能帮你少走一些弯路。
题目背景
设计一个海量游戏排行榜系统,具体场景如下:
- 这是一款竞技类手游,游戏每 5 分钟 开启一局,所有在线玩家可以参与;
- 每天约有 2000 万活跃用户;
- 每局结束后,玩家获得一个分数,系统需要实时计算排名;
- 需要支持的功能包括:实时 Top100 排行榜、查询个人排名、查询附近排名、历史战绩查询、运营数据分析报表。
这是一道典型的系统设计面试题,也是真实业务中常见的场景。
从问题本质开始,而不是从技术名词开始
很多人在回答系统设计题时,容易一上来就说 Redis、Kafka、MySQL、ClickHouse。这样回答不能说错,但容易让人觉得是在背技术名词。工具不是起点,问题才是起点。
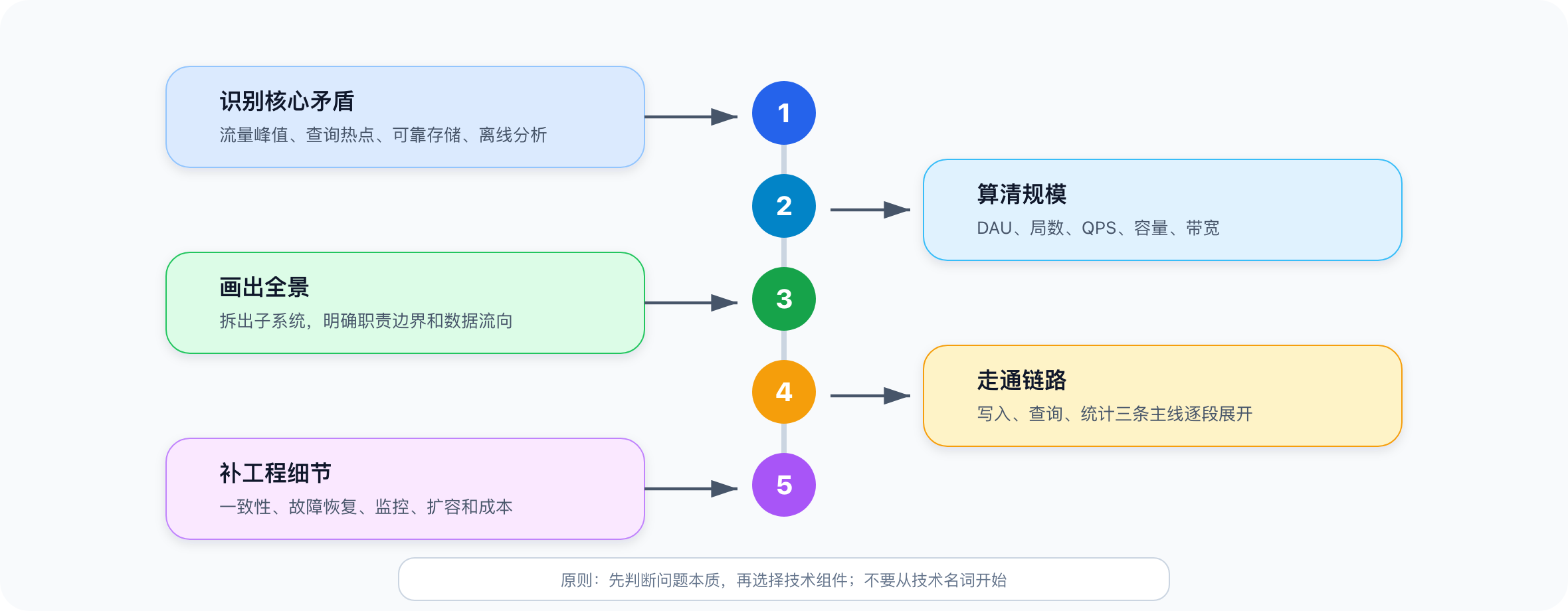
拿到一道系统设计题,正确的展开顺序是:
- 识别核心矛盾:这个系统到底在解决什么问题?
- 算清规模:数据量、QPS、带宽是多少?没有数量级,所有架构判断都是空谈。
- 画出全景:把系统拆成几个子问题,明确职责边界和数据流向。
- 走通链路:分别沿着写入、查询、统计三条主线,逐段设计每个环节。
- 补工程细节:容量评估、一致性取舍、故障恢复、监控指标。
这道题的核心矛盾
回到排行榜这道题,矛盾主要有四个:
- 玩家很多,成绩提交会形成瞬时高峰;
- 排行榜查询很多,不能每次都临时排序;
- 历史战绩必须可靠保存,不能只放缓存;
- 运营分析要扫描大量历史数据,不能压垮在线数据库。
这四个矛盾指向一个结论:
实时排序、异步结算、历史存储和离线分析是四件不同的事,应该让不同的系统各司其职。
明确了这一点,接下来我们按照"算规模 → 画全景 → 走写入链路 → 走查询链路 → 走统计链路 → 补工程细节"的顺序逐步展开。
一、先把规模算清楚
我们先做几个最基本的估算。
1. 每天有多少局
每 5 分钟一局:
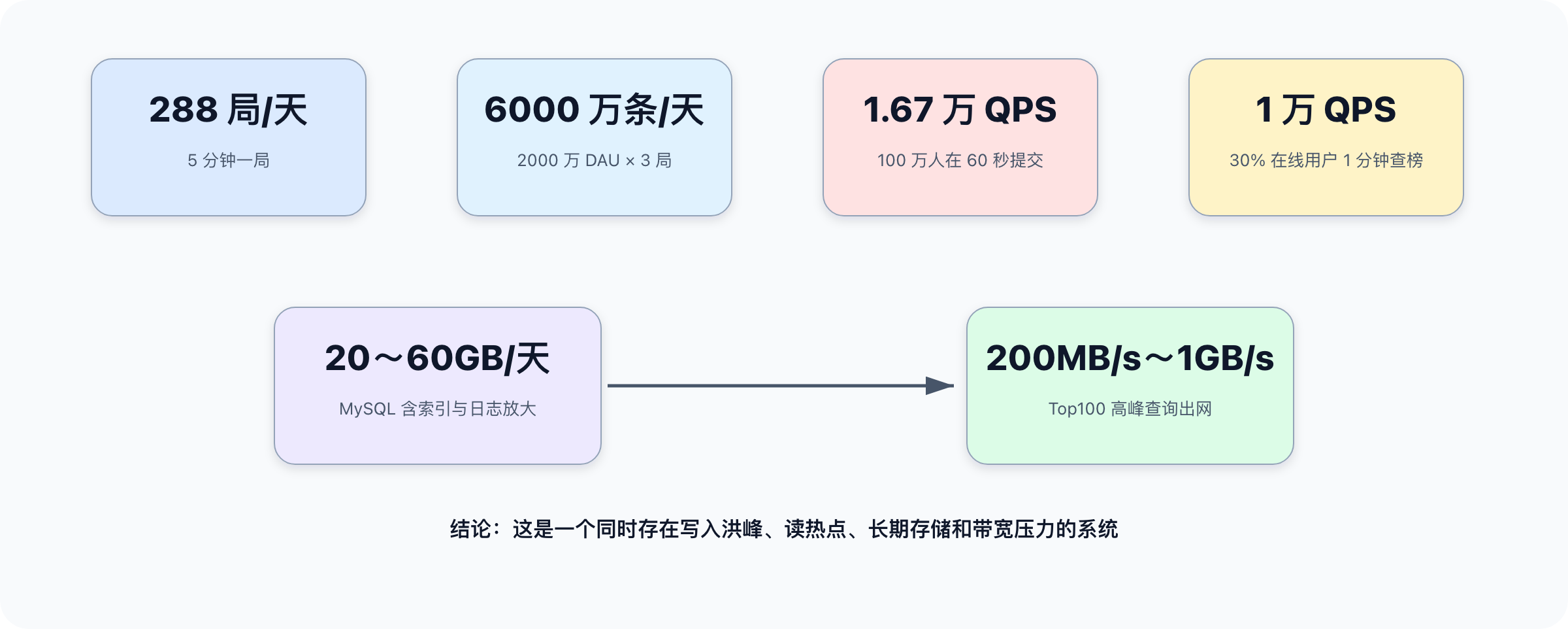
24 * 60 / 5 = 288 局/天
2. 每天有多少战绩
假设每个用户平均每天玩 3 局:
2000万 * 3 = 6000万条战绩/天
平均每局参与人数:
6000万 / 288 ≈ 20.8万 人/局
这只是平均值。如果遇到晚高峰、周末、活动,单局人数可能达到 60 万甚至 100 万。
3. 写入 QPS 大概是多少
如果一局结束后,20 万人成绩在 60 秒内提交:
20万 / 60 ≈ 3333 次写入/秒
如果高峰局 100 万人在 60 秒内提交:
100万 / 60 ≈ 1.67万 次写入/秒
工程上不能刚好按峰值配资源,通常要乘以 2 到 3 倍冗余。也就是说,成绩提交链路至少要按数万 QPS 级别来设计。
4. 查询 QPS 大概是多少
写入 QPS 和查询 QPS 不是同一个数字。查询 QPS 取决于有多少用户会在同一时间打开或刷新排行榜。
例如高峰期有 200 万在线用户,如果其中 10% 在一分钟内查看排行榜:
200万 * 10% / 60 ≈ 3333 QPS
如果活动期间 30% 在线用户在一分钟内查看排行榜:
200万 * 30% / 60 ≈ 1万 QPS
5. 存储容量大概是多少
一条成绩记录包含:
round_id, user_id, score, rank_no, created_at, 状态字段, 扩展字段
如果按一条记录 100 到 200 字节估算:
6000万 * 100B ≈ 6GB/天
6000万 * 200B ≈ 12GB/天
但数据库真实占用远不止这些。还要加上主键索引、二级索引、binlog、undo/redo、行格式和页管理开销、主从副本。所以 MySQL 的实际新增容量往往要按原始数据的 3 到 5 倍估算:
MySQL 实际新增容量 ≈ 20GB 到 60GB/天
保留 180 天,就是数 TB 到十几 TB。这时分库分表、冷热分离、历史归档就不是锦上添花,而是系统能否长期运行的前提。
6. 带宽压力从哪里来
假设 Top100 返回 100 个用户,每个用户包含昵称、头像、分数、排名等信息,平均 200B:
100 * 200B = 20KB/次
如果高峰有 1 万 QPS 查询 Top100:
20KB * 1万 = 200MB/s
如果活动更激烈,排行榜查询达到 5 万 QPS:
20KB * 5万 = 1000MB/s ≈ 1GB/s
这时就必须考虑 Top100 快照缓存、本地缓存、接口字段裁剪、压缩、限流和 CDN 等手段。
所以这个系统既有写入峰值,也有查询峰值。二者都要分别估算。
小结:规模评估汇报
估算可以汇总成一个判断:这不是单一的排行榜问题,而是写入、读取、存储和带宽同时存在压力的综合系统。后续架构设计必须围绕这些数量级展开。
二、宏观架构
算完规模,我们就知道不能用一个数据库解决所有问题。
这个系统应该拆成四层:
| 子系统 | 解决的问题 | 适合的技术 |
|---|---|---|
| 异步结算 | 承接成绩提交高峰,削峰填谷 | Kafka / RocketMQ |
| 实时排行榜 | 查 Top100、查个人排名、查附近排名 | Redis ZSet |
| 历史存储 | 保存原始成绩,支持审计、发奖和历史查询 | MySQL 分库分表 |
| 数据分析 | 做运营报表和大规模统计 | ClickHouse |
四层的分工:
- Kafka 负责缓冲;
- Redis 负责快;
- MySQL 负责事实;
- ClickHouse 负责分析。
一个好的系统,不是让某个组件无所不能,而是让每个组件各司其职。
整体架构和主流程
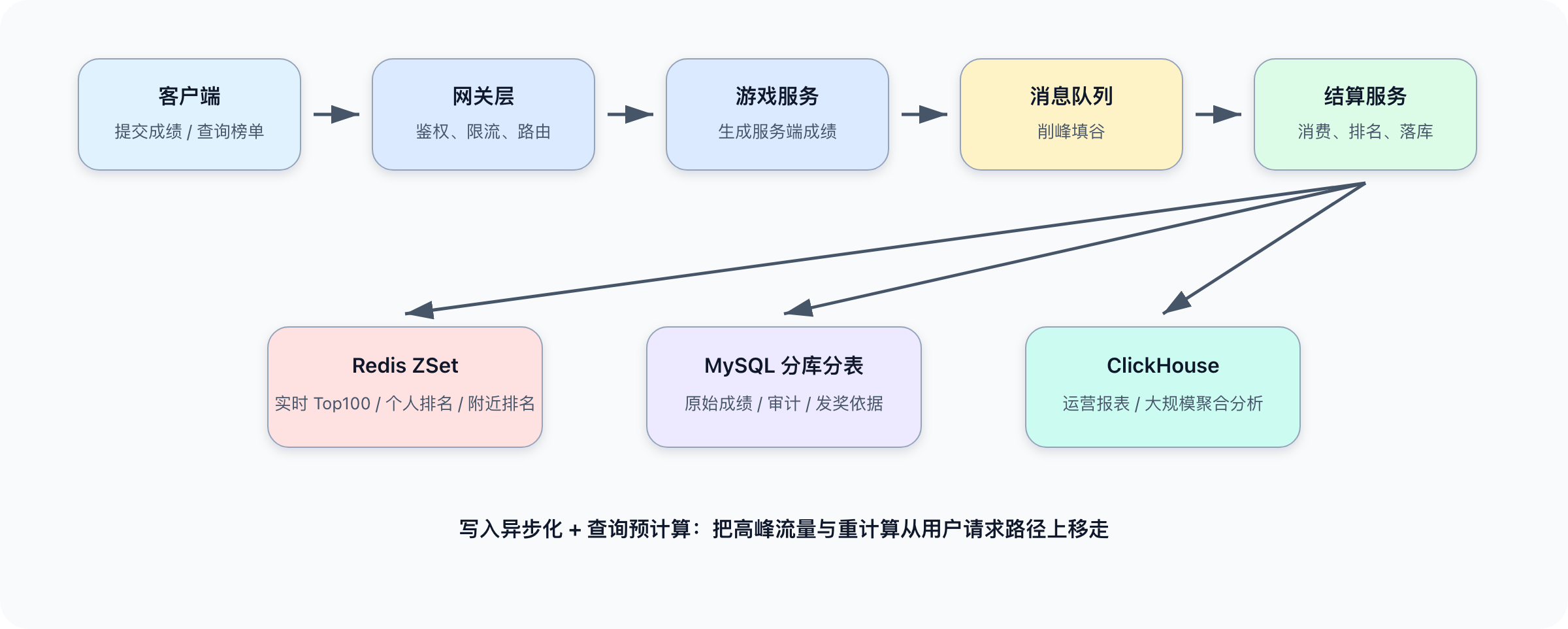
主流程是:
- 玩家完成游戏,游戏服务生成成绩;
- 游戏服务把成绩写入 Kafka;
- 结算服务消费成绩消息;
- 结算服务更新 Redis 排行榜;
- 结算服务批量写入 MySQL;
- 历史明细再同步到 ClickHouse 做分析。
这条链路里有两个关键思想:
第一,写入异步化。不要让游戏服务同步完成所有结算、排名、落库、发奖逻辑。
第二,查询预计算。不要在用户查询排行榜时临时排序,而是在成绩写入时维护好有序结构。
搜索引擎也是这个道理。它不会在用户搜索时才扫描全网,而是提前建好索引。排行榜也一样,不应该在用户查询时才排序。
三、数据写入:从成绩产生到落库
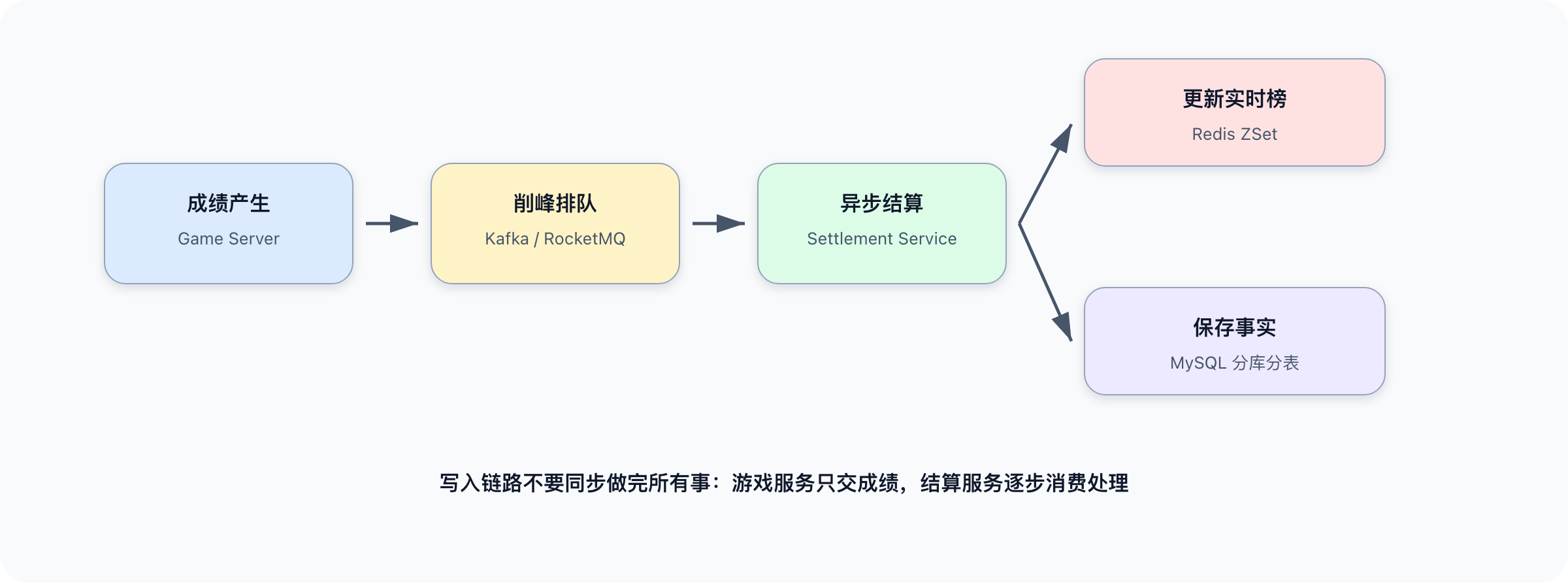
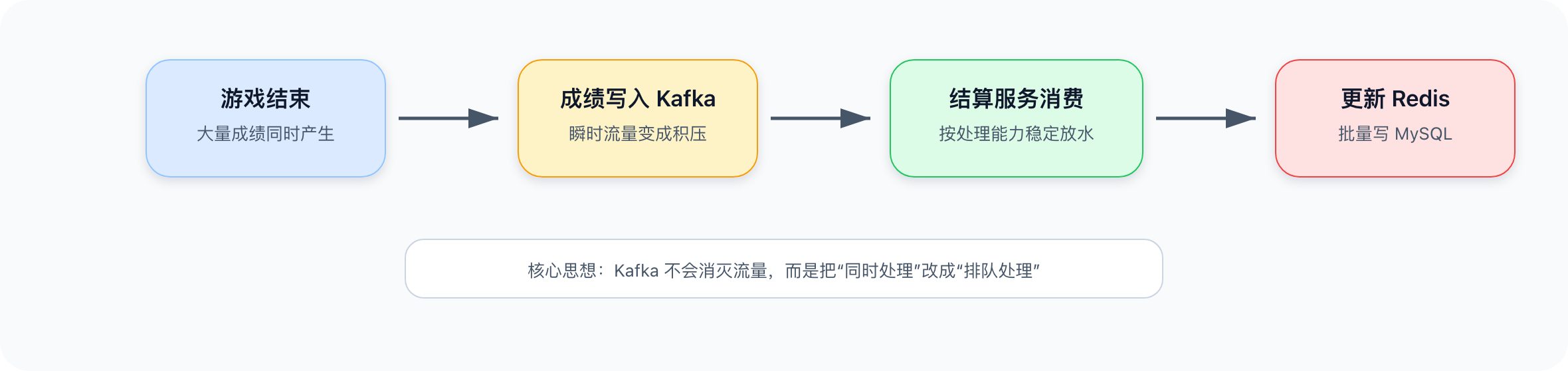
数据写入是整个系统的起点。一局结束时,可能几十万玩家同时提交成绩。这条链路要解决三个问题:承接高峰、更新排名、保存事实。
1. 第一步:Kafka 承接高峰
如果所有成绩请求都同步写 MySQL、更新 Redis、发奖励,游戏服务会被拖垮。
Kafka 的作用可以理解成水库。洪水来的时候,水库先蓄水,再按照下游能承受的速度放水:
Kafka 解决什么问题
| 问题 | Kafka 的作用 |
|---|---|
| 瞬时高峰 | 把瞬时流量变成队列积压 |
| 服务耦合 | 游戏服务只负责提交成绩,结算服务负责处理成绩 |
| 水平扩展 | 多个 Consumer 并行消费多个 Partition |
Kafka 不能让流量消失,它只是把"同时发生"的压力,变成"排队处理"的压力。
如果一局瞬间来了 100 万条成绩,而结算服务每秒处理 2 万条:
100万 / 2万 = 50秒
这波流量就会被摊平到 50 秒内处理。
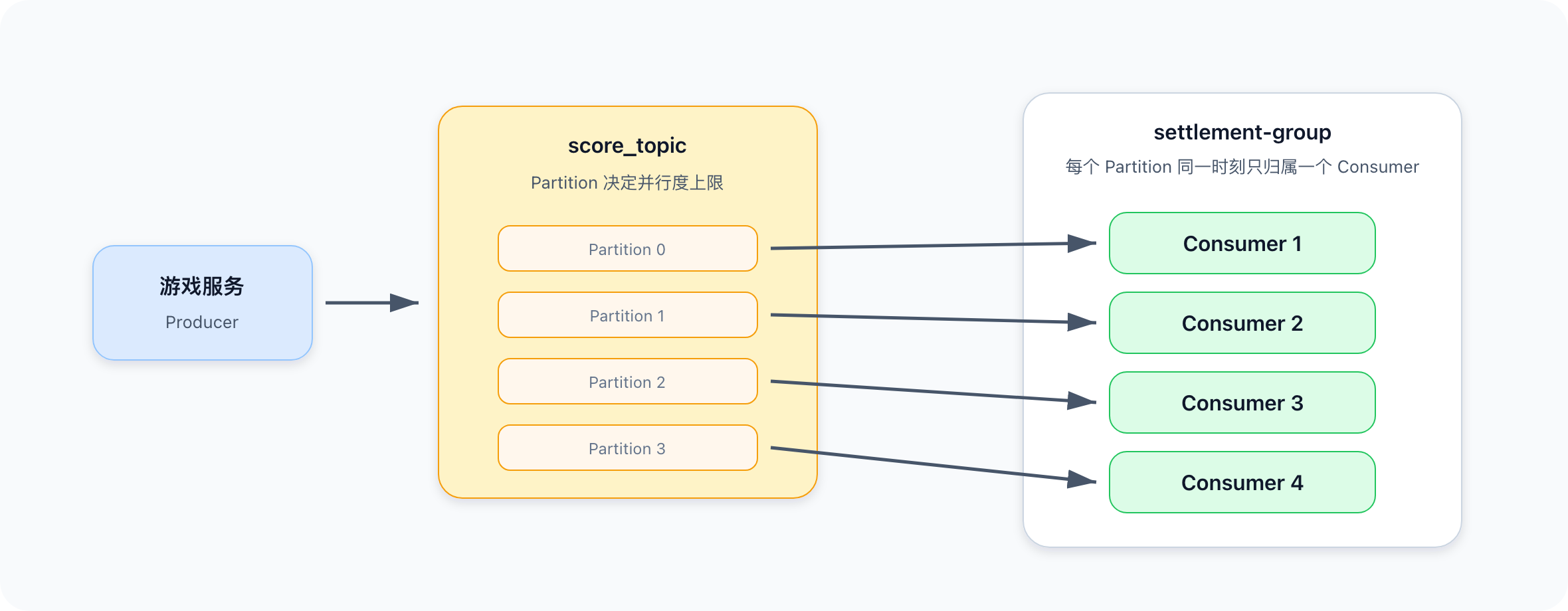
Topic、Partition、Consumer 如何理解
Topic:一类消息的集合
Partition:Topic 下面的物理分片
Producer:写消息的人
Consumer:读消息的人
Consumer Group:一组协同消费的人
Offset:消费到哪里了
以成绩消息为例:
Topic: score_topic
Partition: score_topic-0, score_topic-1, ... score_topic-63
Producer: 游戏服务
Consumer: 结算服务
Consumer Group: settlement-group
Topic 像一本书的名字,Partition 像这本书拆成的很多卷。消息真正写入的是某个 Partition。
Kafka 高吞吐的原因之一是:
- Partition 内顺序追加写;
- 多个 Partition 并行读写;
- 多个 Consumer 并行消费。
Consumer Group 和并行度
一个 Consumer Group 里可以有多个 Consumer。
但有一个重要规则:
同一个 Consumer Group 内,一个 Partition 同一时刻只能被一个 Consumer 消费。
如果:
score_topic 有 64 个 Partition
settlement-group 有 16 个 Consumer
那么平均每个 Consumer 消费 4 个 Partition。
如果 Consumer 增加到 64 个,大约每个 Consumer 消费 1 个 Partition。
如果 Consumer 增加到 100 个,多出来的 36 个 Consumer 会闲着,因为 Partition 数量决定了并行度上限。
所以 Kafka 扩容不是简单加机器,还要提前设计 Partition 数。
为什么同一局最好进同一个 Partition
Kafka 只能保证 Partition 内有序,不能保证整个 Topic 全局有序。
如果同一局成绩分散到很多 Partition,不同 Consumer 处理速度不同,就很难判断:
这一局的成绩是不是已经全部处理完了?现在能不能生成最终 Top100?
所以普通规模下,可以按 round_id 分区:
partition = round_id % partition_count
这样同一局成绩进入同一个 Partition,顺序和完成状态更容易控制。
但这也有代价:如果某一局特别大,这个 Partition 会成为热点。
更完整的策略是:
- 普通规模:按 round_id 分区,简化一致性;
- 超大规模:按
round_id + shard_id分区,再做分片 TopK 归并。
Kafka 要监控什么
队列不是魔法。如果长期生产速度大于消费速度,积压会越来越多。
因此必须监控:
- 生产 QPS;
- 消费 QPS;
- Consumer Lag;
- 消息堆积量;
- 单条消息处理耗时;
- 重试和死信数量。
能看到这些指标,才算真正把 Kafka 用进了工程系统。
2. 第二步:更新 Redis 排行榜
结算服务消费成绩后,第一件事是更新实时排行榜。
为什么用 Redis ZSet
如果用 MySQL 实时查 Top100:
SELECT * FROM round_score WHERE round_id = ? ORDER BY score DESC LIMIT 100;
在小数据量下没问题,但在一局几十万、上百万人时,高并发执行这种排序会给数据库带来很大压力。MySQL 擅长保存事实和处理事务,不适合承担高频实时排序。
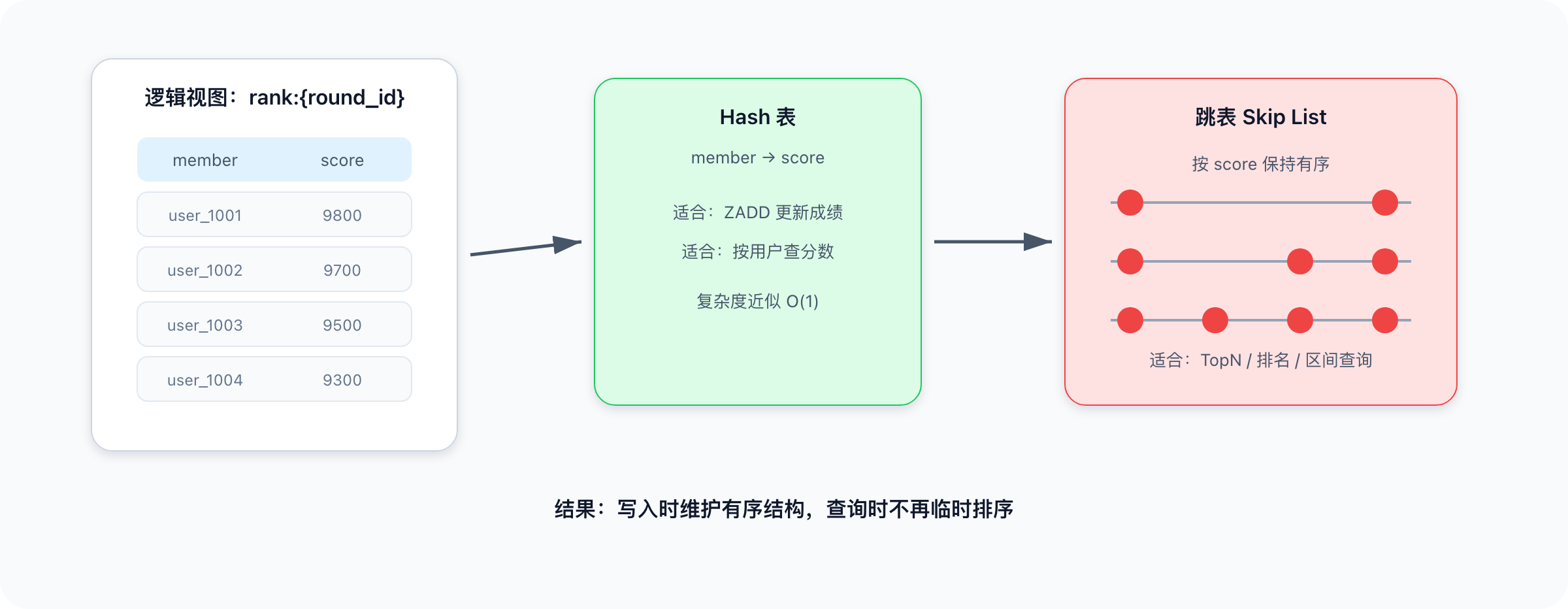
Redis ZSet(Sorted Set,有序集合)可以理解成一张逻辑表:
| member | score |
|---|---|
| user_1001 | 9800 |
| user_1002 | 9700 |
| user_1003 | 9500 |
在排行榜里:
member是用户 ID;score是玩家分数;- Redis 自动按照 score 维护顺序。
ZSet 底层为什么适合排行榜
Redis ZSet 通常由两类结构配合实现:
- Hash 表:根据 member 快速找到 score,适合更新某个用户成绩。
- 跳表 Skip List:按 score 保持有序,适合查排名、查区间、查 TopN。
跳表可以理解成"带多级索引的链表"。普通链表只能一步一步走,跳表可以通过索引层跳着走。它在性能、实现复杂度和可维护性之间取得了很好的平衡。
写入命令
每一局一个排行榜 Key:
rank:{round_id}
写入成绩:
ZADD rank:{round_id} score user_id
结算服务每消费一条成绩消息,就执行一次 ZADD。Redis 会自动维护有序结构,后续查询不需要临时排序。
同分处理
真实系统里同分很常见。如果规则是"同分时完成时间更早者排名更靠前",可以把分数和完成时间编码进一个 Redis score:
redis_score = game_score * 1_000_000_000 + (MAX_TIMESTAMP - finish_time)
含义是:
game_score越大,排名越靠前;- 分数相同,完成时间越早,排名越靠前。
不过 Redis ZSet 的 score 是 double 类型,数值过大时要注意精度。如果分数和时间范围很大,可以改成 Redis 只按主分数排序,同分用户在应用层二次排序。
超大单局:分片写入
如果单局有 1000 万玩家,一个 Redis Key 会带来问题:单 Key 太大、写入集中到一个节点、热点 Key 成为瓶颈。
这时把一局排行榜拆成多个分片:
rank:{round_id}:0
rank:{round_id}:1
...
rank:{round_id}:63
分片规则:
shard_id = user_id % 64
结算服务根据 user_id 决定写入哪个分片。每个分片内部仍然用 ZSet,压力被分散到多个 Redis 节点。
3. 第三步:事实落库 MySQL
Redis 负责实时排名,但不能作为唯一事实来源。历史成绩、发奖依据、客服申诉、审计回放,都需要可靠存储。
表结构设计
对局表:
CREATE TABLE game_round (
round_id BIGINT PRIMARY KEY,
start_time DATETIME,
end_time DATETIME,
status TINYINT
);
成绩事实表:
CREATE TABLE round_score (
id BIGINT PRIMARY KEY,
round_id BIGINT,
user_id BIGINT,
score BIGINT,
rank_no INT,
created_at DATETIME,
UNIQUE KEY uk_round_user(round_id, user_id),
INDEX idx_round_score(round_id, score DESC),
INDEX idx_user_round(user_id, round_id)
);
三个关键索引:
uk_round_user(round_id, user_id):保证同一局同一用户只有一条最终成绩;idx_round_score(round_id, score DESC):用于补偿、审计、离线查询;idx_user_round(user_id, round_id):用于查询用户历史战绩。
批量写入
结算服务应该批量写 MySQL,而不是每条成绩一个事务:
INSERT INTO round_score (...)
VALUES (...), (...), (...)
ON DUPLICATE KEY UPDATE score = VALUES(score);
批量写入可以显著降低事务和网络开销。
round_id 从哪里来
round_id 不建议由每台业务服务器各自用本机时间计算。一种看似简单的写法是 round_id = timestamp / 300,但这只能作为理解模型。原因有两个:
- 时间回拨:服务器时间可能因为 NTP 校时、虚拟机迁移等原因向后跳;
- 时间差异:不同业务服务器的本机时间可能相差几十毫秒甚至更多。
更稳妥的做法是引入一个权威的 对局调度服务 Round Service:
Round Service 预先生成 game_round
业务服务只查询当前 round_id
成绩提交时必须携带服务端确认过的 round_id
例如预先生成当天所有对局:
round_id start_time end_time
202605170001 00:00:00 00:05:00
202605170002 00:05:00 00:10:00
202605170003 00:10:00 00:15:00
业务服务通过缓存或接口获取当前对局:
current_round_id = RoundService.getCurrentRound()
这样对局边界由一个权威服务控制,业务服务器之间不会各自判断局号,时间回拨不会直接导致 round_id 回退。
分库分表
当数据量持续增长,单库单表迟早会遇到问题:单表过大、索引膨胀、写入变慢、备份恢复困难。
分库分表的本质,是把集中压力拆开。
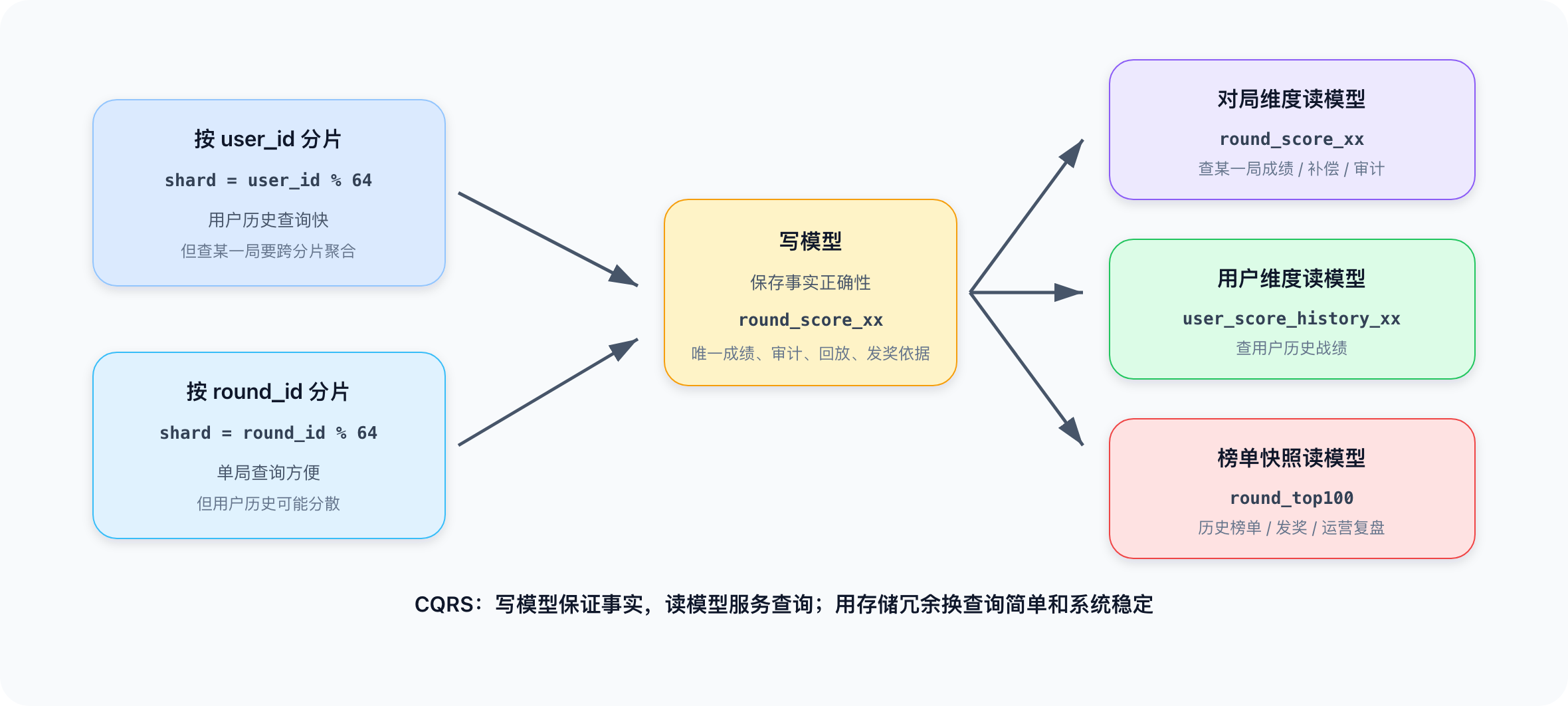
按 user_id 分片:
shard = user_id % 64
优点:查询用户历史很快。缺点:查询某一局排行榜时需要跨很多分片聚合。
按 round_id 分片:
shard = round_id % 64
优点:查询某一局数据很方便。缺点:查询用户历史时可能分散到很多分片。
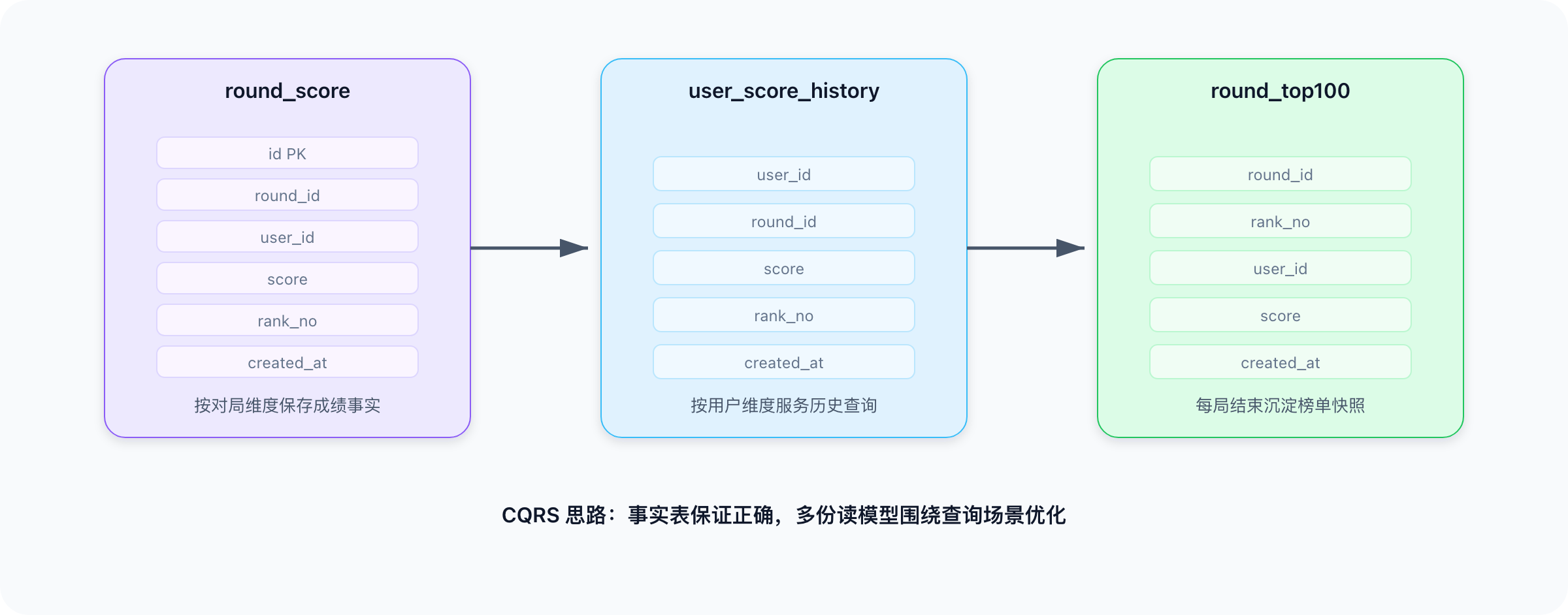
推荐:双维度读模型
排行榜系统同时有两类查询,这两类访问模式天然冲突。更合理的做法是维护多份读模型:
round_score_xx:按对局维度保存成绩事实
user_score_history_xx:按用户维度保存用户历史
round_top100:保存每局 Top100 快照
这就是 CQRS 思路:写模型保证事实正确,读模型围绕查询场景优化。
索引不能贪多
对于每天 6000 万条写入的系统,索引设计要克制。每一个索引都是写入成本、存储成本、维护成本和复制成本。好的工程设计不是把所有可能都铺满,而是抓住核心访问路径。
四、数据查询:从实时榜到历史榜
写入链路解决了"数据怎么进来",查询链路解决"数据怎么出去"。排行榜的查询场景可以分为实时查询和历史查询两大类。
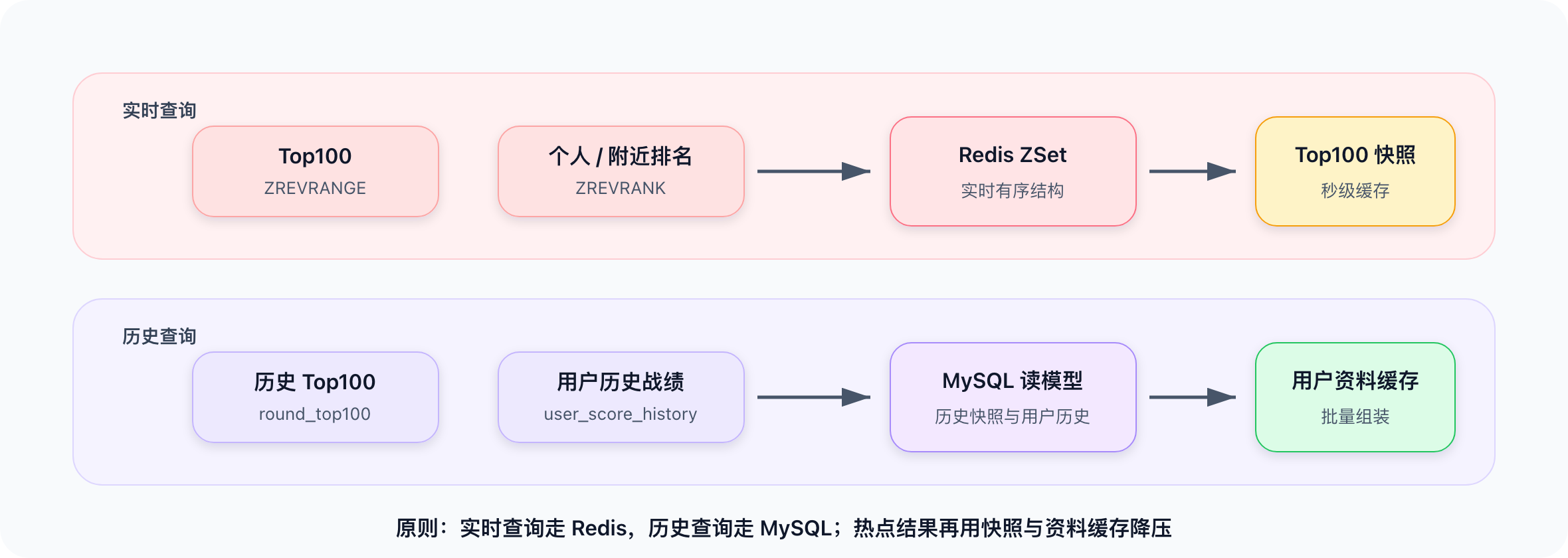
1. 实时 Top100
当前局查 Redis:
ZREVRANGE rank:{round_id} 0 99 WITHSCORES
因为 Redis ZSet 已经维护了有序结构,这个查询不需要临时排序,直接取前 100 个元素即可。
这背后的思想是:
查询路径上不要做重计算。
如果每次用户打开排行榜都重新排序,就会把计算压力转移到用户访问路径上。访问量越高,系统越危险。正确做法是把排序成本分摊到成绩写入过程中,让查询变成一次简单读取。
2. 个人排名与附近排名
查询用户排名:
ZREVRANK rank:{round_id} user_id
查询附近排名(假设用户排名为 rank):
ZREVRANGE rank:{round_id} rank-5 rank+5 WITHSCORES
这些命令覆盖了排行榜的核心需求。
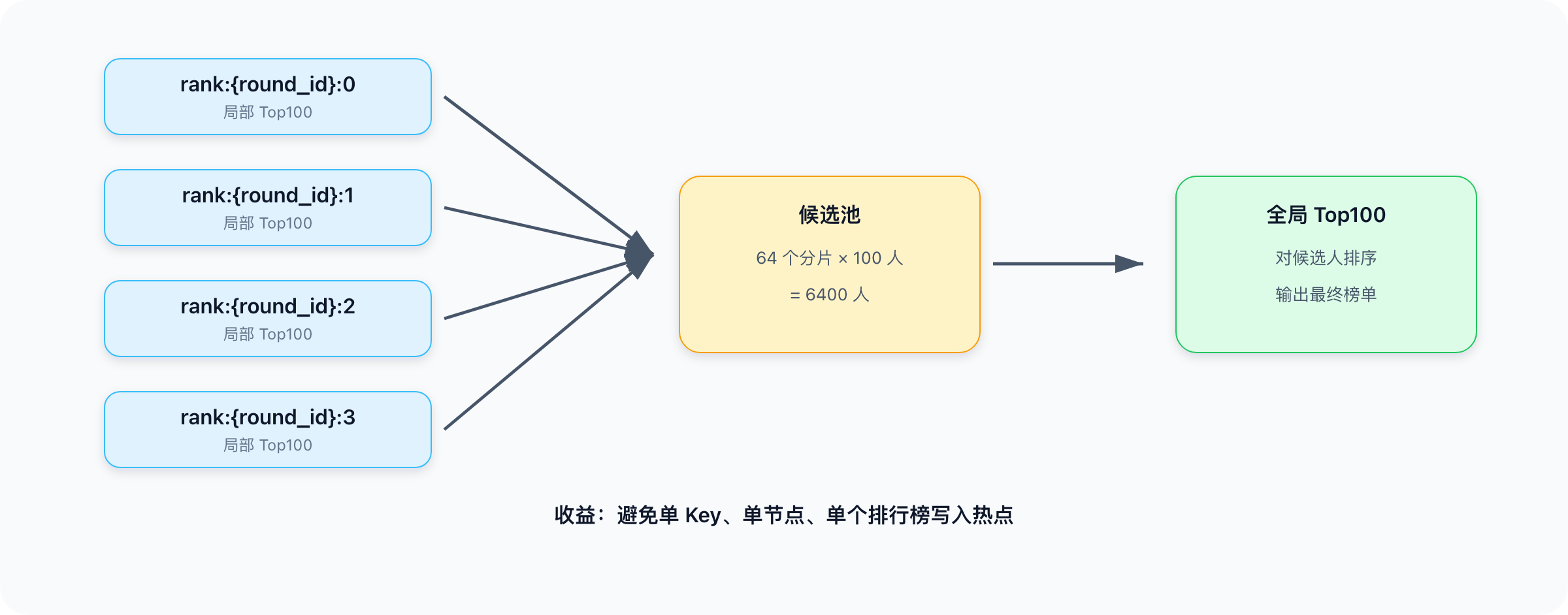
3. 超大单局的全局 Top100
如果使用了分片写入(64 个分片),查询 Top100 需要归并:
每个分片取局部 Top100:
ZREVRANGE rank:{round_id}:{shard_id} 0 99 WITHSCORES
64 个分片,每个取 100 人:
64 * 100 = 6400 人
最后只需要对 6400 个候选人排序,就能得到全局 Top100。
这相当于先在 64 个赛区选出前 100 名,再让这些候选人参加总决赛。本质上,这是把一个大排序问题,变成多个小排序问题加一次小规模归并。
4. 历史 Top100
每局结束后,要把 Top100 写入 MySQL:
CREATE TABLE round_top100 (
round_id BIGINT,
rank_no INT,
user_id BIGINT,
score BIGINT,
created_at DATETIME,
PRIMARY KEY(round_id, rank_no)
);
为什么要落库?因为 Top100 不只是展示用,还关系到历史榜单查询、奖励发放、赛季统计、客服申诉和运营复盘。
查询历史 Top100:
SELECT * FROM round_top100 WHERE round_id = ? ORDER BY rank_no ASC;
5. 用户历史战绩
查用户维度历史表:
SELECT * FROM user_score_history WHERE user_id = ? ORDER BY round_id DESC LIMIT 20;
6. 查询性能优化
Top100 快照缓存
如果 Top100 查询 QPS 很高,每次都执行 ZREVRANGE 0 99 也可能形成热点。真正的压力通常来自三件事:
- 大量请求集中打到同一个排行榜 Key;
- 每次查询都要再批量查询用户昵称、头像、等级等资料;
- Top100 响应体较大,网络出流量很高。
因此,可以维护一个 Top100 快照:
top100:{round_id}
这个快照存成已经组装好的结果(JSON、MessagePack 或压缩后的二进制内容)。排行榜服务每隔 1 秒更新一次,查询接口直接读取快照。
好处是:
- 避免每个请求都查 ZSet;
- 避免每个请求都批量查用户资料;
- 可以把 Top100 结果作为一个整体缓存。
三层缓存
更完整的设计是三层缓存:
ZSet 原始排行榜
↓ 每 1 秒生成一次
Redis Top100 快照
↓ 应用层短 TTL 缓存
接口直接返回
应用层本地缓存可以设置 0.5 到 1 秒 TTL。这样即使有 1 万 QPS 打到接口层,也不一定每个请求都访问 Redis。

这是一种典型取舍:
- 绝对实时:每次查 ZSet,结果最新,但压力更大;
- 秒级实时:读 Top100 快照,允许 1 秒延迟,系统更稳;
- 极高 QPS:在快照之上再加应用本地缓存、压缩、限流和降级。
工程设计常常是用一点可接受的延迟,换取系统稳定性。
用户资料组装
排行榜不应该只返回 user_id 和 score,还需要昵称、头像、等级。但这些资料不应该塞进排行榜 Key 里。
推荐流程:
先从 ZSet 拿 user_id 和 score
↓
批量查询用户资料缓存
↓
组装返回结果
例如:
ZREVRANGE rank:{round_id} 0 99 WITHSCORES
MGET user_profile:{user_id1} user_profile:{user_id2} ...
这样用户改头像或昵称时,只需要更新用户资料缓存,不需要重建排行榜。
五、数据统计:从明细到报表
MySQL 保存了历史成绩,但运营分析需要扫描大量数据做聚合统计。如果直接在 MySQL 上跑分析查询,会压垮在线业务。因此需要一个专门的分析系统。
1. 为什么需要 ClickHouse
MySQL 和 ClickHouse 的设计目标不同。
MySQL 更像账本系统,擅长:查某一行、改某一行、保证事务一致性、处理在线业务请求。
ClickHouse 更像统计系统,擅长:扫描很多行、只读取少数列、做聚合计算、快速生成报表。
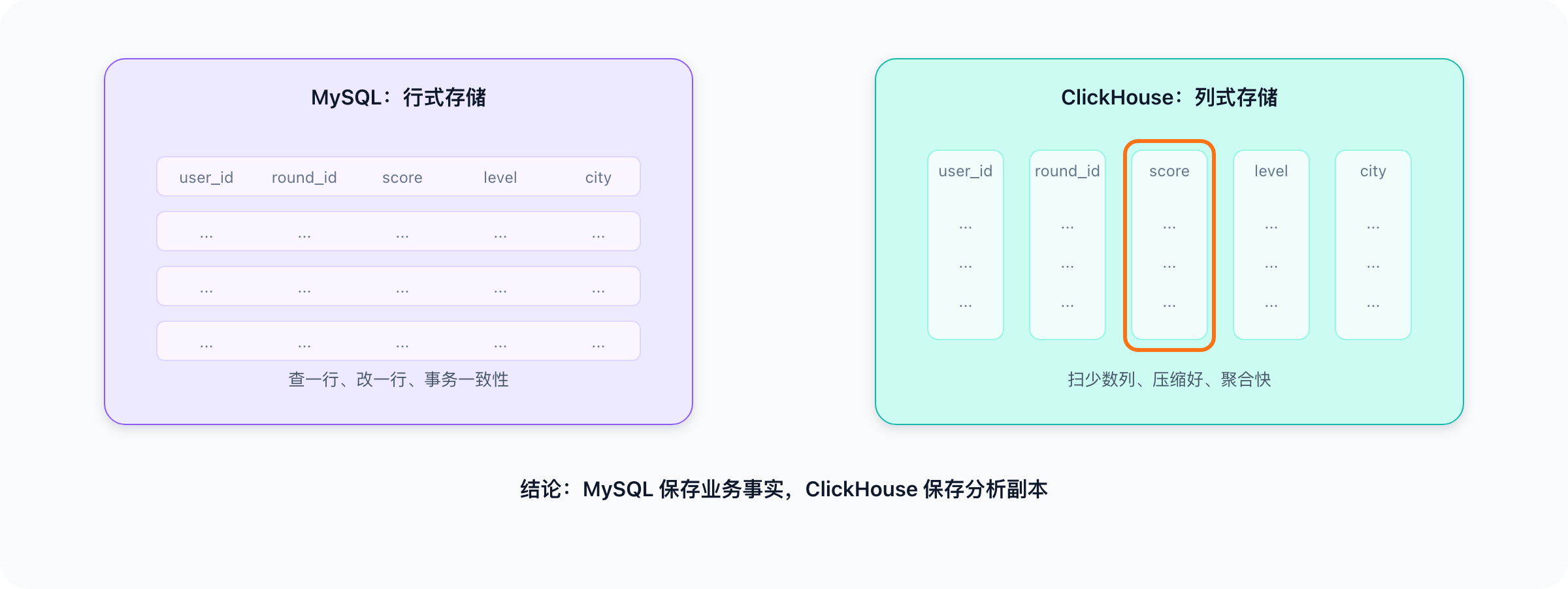
2. 行式存储 vs 列式存储
MySQL 通常是行式存储:
第1行: user_id, round_id, score, level, city, created_at...
第2行: user_id, round_id, score, level, city, created_at...
如果只想统计 score 平均值,MySQL 也可能读取很多无关字段。
ClickHouse 是列式存储:
user_id列: ...
round_id列: ...
score列: ...
level列: ...
如果只统计 score,它主要读取 score 这一列。读得少,自然就快。
3. 压缩率更高
同一列数据类型相同、分布相似,因此容易压缩。比如 level 这一列可能大量重复:
10, 10, 10, 11, 11, 12, 12...
列式存储压缩率高,带来两个好处:磁盘占用更低、查询时读盘更少。很多分析查询的瓶颈不是 CPU,而是 I/O。读得少,就会快很多。
4. 向量化执行
ClickHouse 不是一行一行处理,而是成批处理一列数据。
可以理解为:
- MySQL 像逐行核对账本;
- ClickHouse 像一次处理一整列数字。
现代 CPU 对连续批量数据处理非常友好,因此 ClickHouse 做 SUM、COUNT、AVG、GROUP BY 这类统计很快。
5. MergeTree、分区键和排序键
ClickHouse 常用 MergeTree 引擎。它会按照分区和排序键组织数据。
例如按日期分区:
PARTITION BY toYYYYMMDD(created_at)
ORDER BY (round_id, user_id)
这样查询某一天、某一局的数据时,可以跳过大量无关数据。
6. ClickHouse 不适合做什么
ClickHouse 不适合:高频单行更新、强事务、用户提交成绩的在线写路径、替代 MySQL 做业务主库。
正确分工是:
MySQL 保存业务事实
ClickHouse 保存分析副本
数据可以通过 Kafka 或定时任务从 MySQL / 消息流同步到 ClickHouse。
六、工程细节补充
1. Redis 容量和配置怎么估算
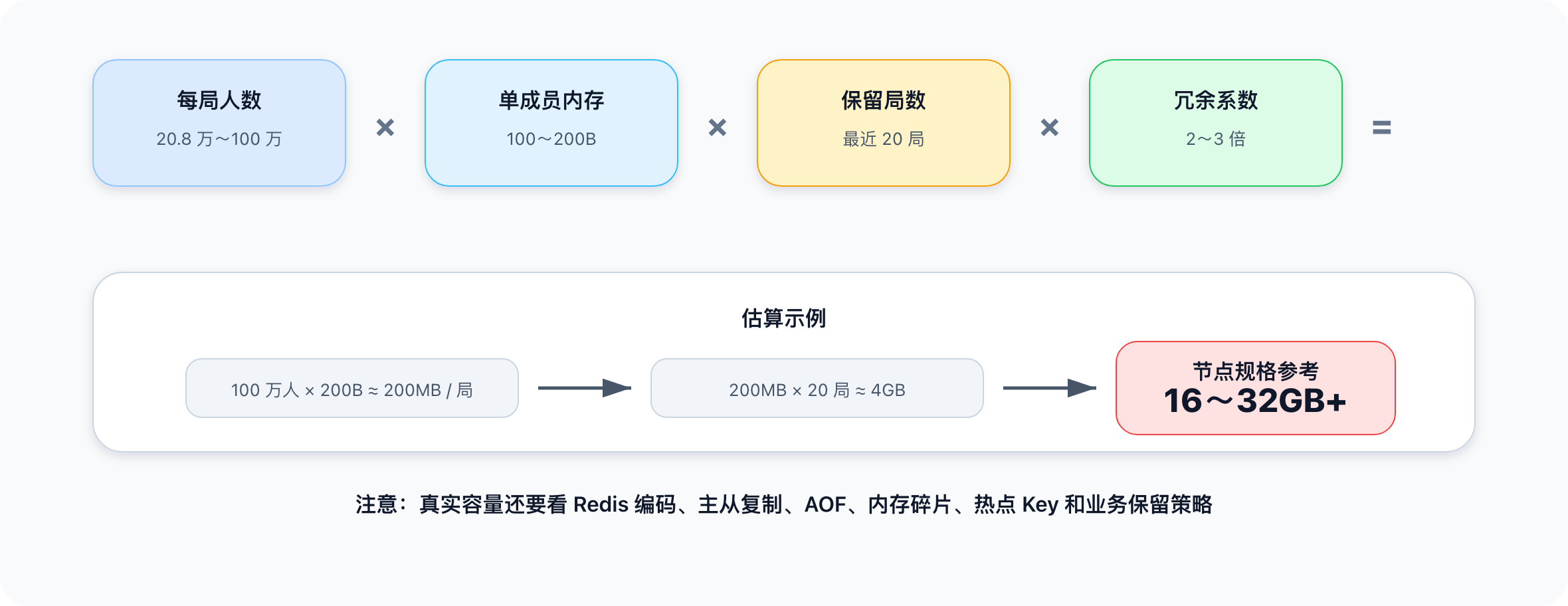
ZSet 中每个成员不仅有 user_id 和 score,还有 Hash 表、跳表节点、Redis 对象和内存分配开销。工程估算时,可以粗略按每个成员 100 到 200 字节 估算。
平均每局 20.8 万人:
20.8万 * 200B ≈ 40MB/局
高峰局 100 万人:
100万 * 200B ≈ 200MB/局
如果同时保留最近 20 局完整排行榜:
200MB * 20 = 4GB
再考虑主从复制、AOF、内存碎片和安全冗余,至少乘以 2 到 3 倍。因此 Redis 节点可能需要按 16GB 到 32GB 内存 级别考虑。
选 Redis 机器至少看四个指标:
| 资源 | 关注点 | 原因 |
|---|---|---|
| 内存 | 能保存多少排行榜成员 | ZSet 是内存结构 |
| CPU | 能处理多少 ZADD、ZREVRANK | Redis 命令执行会消耗 CPU |
| 网络 | Top100 查询返回量 | 榜单查询会产生大量出网流量 |
| 副本 | 主从复制和故障切换 | 故障时要快速恢复 |
2. Redis 数据生命周期
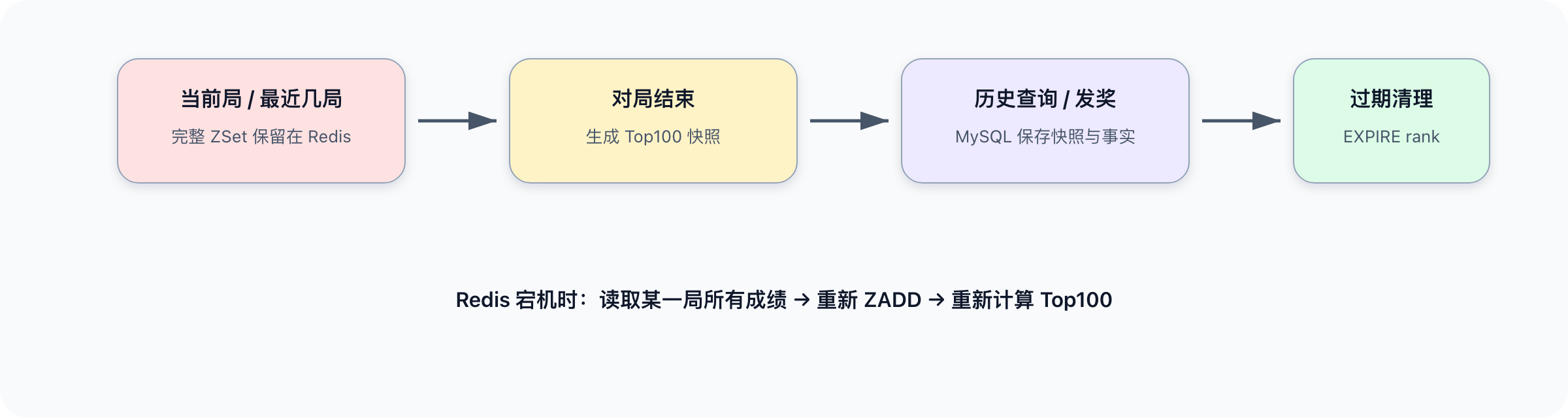
Redis 不应该永久保存所有局的完整排行榜。常见做法是:
- 当前局和最近几局完整保留在 Redis;
- 每局结束后生成 Top100 快照写入 MySQL;
- 给完整排行榜设置过期时间。
例如:
EXPIRE rank:{round_id} 86400
表示完整榜单保留一天。
Redis 宕机怎么办
不能把唯一事实放在 Redis 里。需要两层保护:
- Redis 开启 AOF 或 RDB,降低故障损失;
- Kafka 和 MySQL 保存原始成绩,必要时可以重放或重建排行榜。
重建流程是:
读取某一局所有成绩 → 重新 ZADD 到 rank:{round_id} → 重新计算 Top100
没有原始事实,就没有重建能力。
3. 一致性取舍
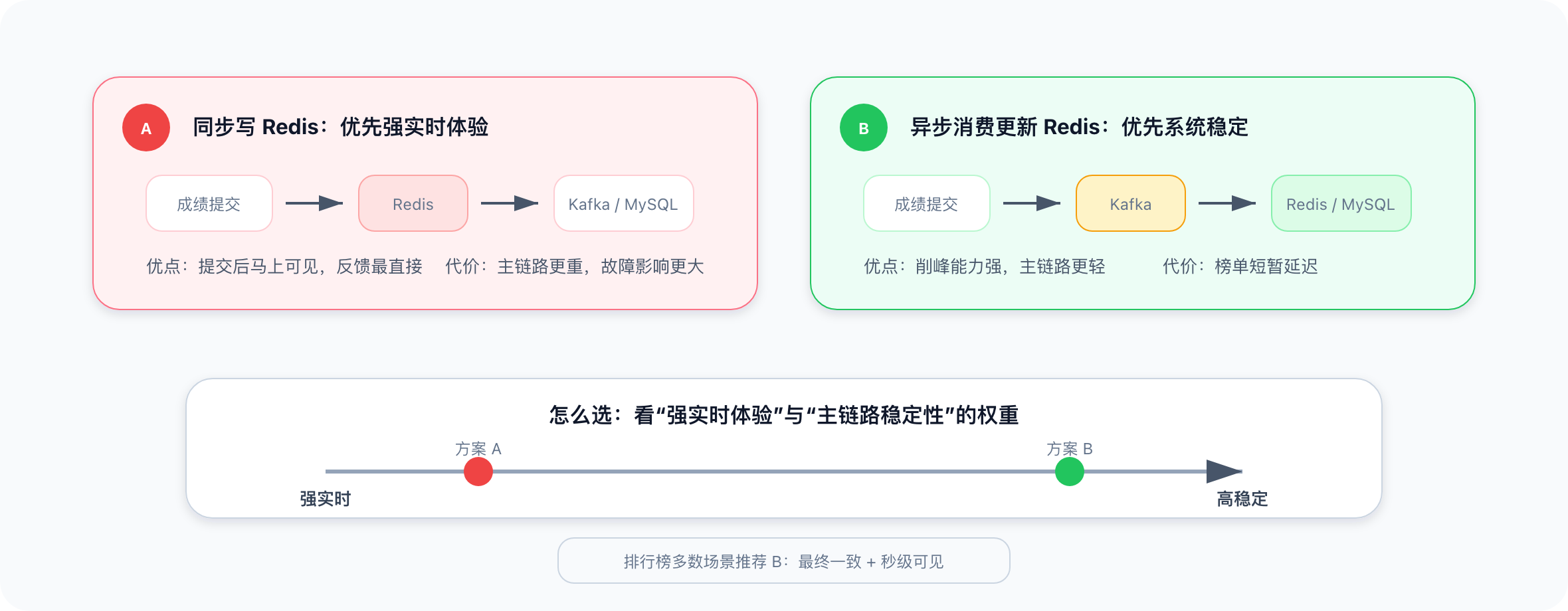
排行榜通常可以接受短暂的最终一致性:
- 成绩提交后,不一定马上出现在榜单;
- Kafka 消费后,几百毫秒到几秒内可见;
- 最终以结算服务落库结果为准。
如果业务要求"提交后立刻可见",可以在游戏服务中同步写 Redis,再异步写 Kafka 和 MySQL。但这样会让游戏服务链路变重。
| 方案 | 优点 | 代价 |
|---|---|---|
| 同步写 Redis | 玩家立刻看到排名 | 主链路更重,故障影响更大 |
| 异步消费更新 Redis | 架构更稳,削峰能力更强 | 有短暂延迟 |
工程设计不是追求某个指标的极致,而是在用户体验、稳定性和成本之间找平衡。
4. 全链路资源评估方法

Redis 评估
Redis内存 ≈ 每局人数 * 单成员内存 * 保留局数 * 冗余系数
冗余系数通常取 2 到 3。
Kafka 评估
写入带宽 ≈ 消息大小 * 峰值QPS * 副本数
如果单条消息 200B,峰值 2 万 QPS,3 副本:
200B * 2万 * 3 ≈ 12MB/s
还要加消费者读取带宽。
MySQL 评估
MySQL容量 ≈ 每日行数 * 单行估算大小 * 索引放大系数 * 保留天数 * 副本数
数据生命周期设计:
- 近 7 到 30 天:在线 MySQL 热查询;
- 近 90 到 180 天:分区表或归档库;
- 更久历史:ClickHouse 或对象存储归档。
ClickHouse 评估
关注每天导入量、压缩率、分区键和排序键是否合理、报表查询并发。ClickHouse 的容量通常因为压缩而比 MySQL 明细小,但具体大小取决于字段类型和重复度。不要凭感觉,要拿样本数据压测。
网络和接口层评估
如果 Top100 一次返回 20KB,高峰 1 万 QPS:
20KB * 1万 = 200MB/s
接口层要考虑:字段裁剪、gzip 压缩、Top100 快照缓存、用户资料批量查询、CDN 缓存静态头像、限流和降级。
容量评估的目的,不是一次算得百分之百准确,而是知道瓶颈可能在哪里,并提前设计观察指标和扩容手段。
七、最终方案总结
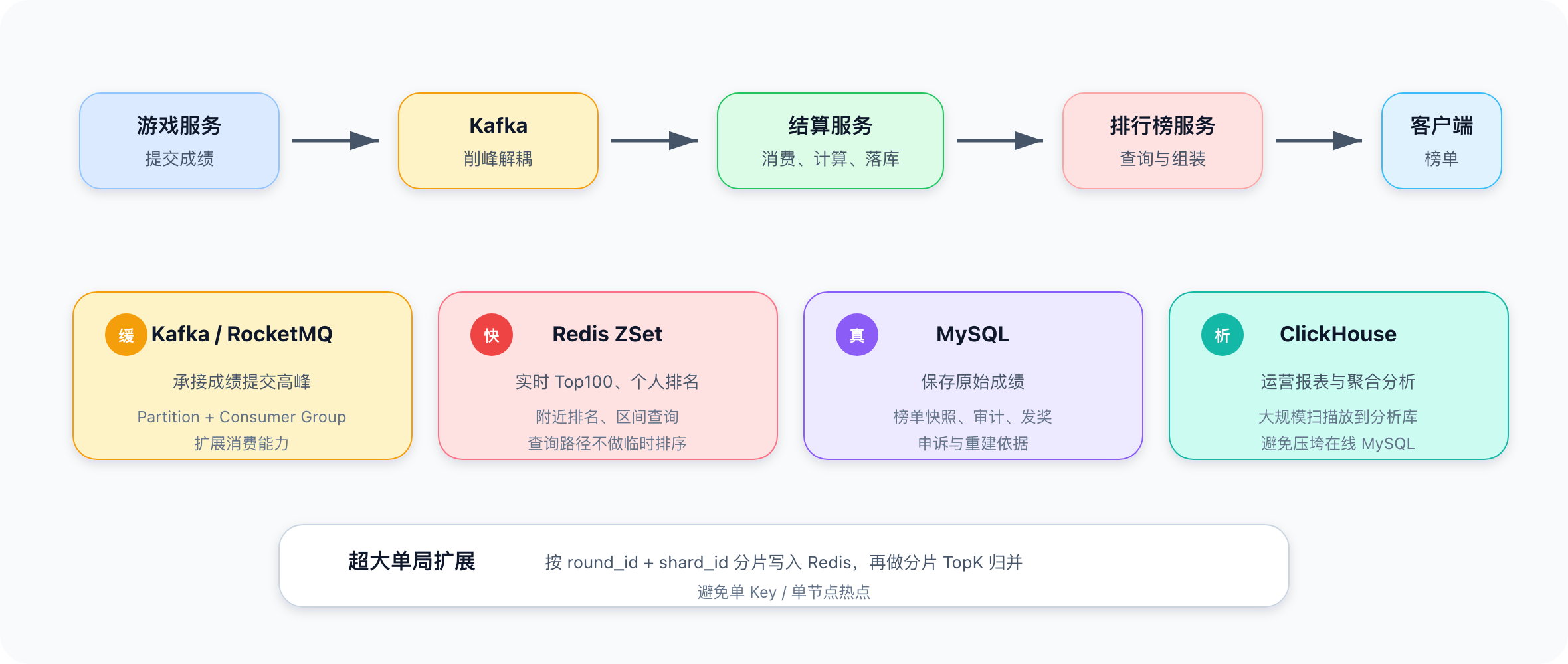
完整方案可以概括为一句话:
Kafka 做削峰解耦,Redis 做实时排名,MySQL 做事实存储,ClickHouse 做历史分析;当单局规模过大时,用分片 TopK 降低热点和排序压力。
核心技术选型:
| 功能 | 技术方案 | 原因 |
|---|---|---|
| 成绩提交削峰 | Kafka / RocketMQ | 吸收瞬时流量,异步结算 |
| Kafka 分区 | round_id 或 round_id + shard_id | 在顺序性和扩展性之间取舍 |
| 实时排行榜 | Redis ZSet | 天然支持按分数排序、查排名、查 TopN |
| 超大单局榜单 | 分片 TopK | 避免单 Key 和单节点热点 |
| 历史战绩 | MySQL 分库分表 | 保证事实可靠、支持审计和查询 |
| 历史 Top100 | MySQL 快照表 | 支持历史查询和奖励发放 |
| 海量分析 | ClickHouse | 列式存储、压缩、向量化执行,适合聚合分析 |
| 用户资料展示 | Redis / Memcached 缓存 | 避免排行榜中冗余用户资料 |
九、这道题真正考什么
这道题表面上考排行榜,实际上考的是系统设计的基本功。
第一,能不能先算规模。没有数量级,就没有架构判断。
第二,能不能区分不同问题。实时排名、历史存储、运营分析不是同一个问题,不应该用同一个系统解决。
第三,能不能把重计算前置。Top100 不应该在查询时临时排序,而应该通过 ZSet 持续维护。
第四,能不能理解工程取舍。强实时和最终一致、单 Key 和分片、单表和多读模型,没有绝对正确,只有在业务约束下更合适。
技术的学习,最忌讳把名词背得很多,却不知道它们为什么出现。Redis、Kafka、MySQL、ClickHouse 都不是孤立的工具,它们是为了解决不同矛盾而出现的工程选择。
如果能把这个道理讲清楚,这道题就不只是答对了,而是讲出了系统设计的味道。